Strings
Reference: Strings
What is a sequence object?
A sequence object is a container of items accessed via index. Text strings are technically sequence objects.
Sequence Object Types:
- String
- Lists
- Tuples
- Range Objects
Each of the above support built in functions and slicing.
Sequence Objects: Strings
Strings are immutable! They need to be reassigned. There are two independent types of strings:
- ASCII: Default strings for Python 2
- Unicode (UTF-8): Default strings for Python 3
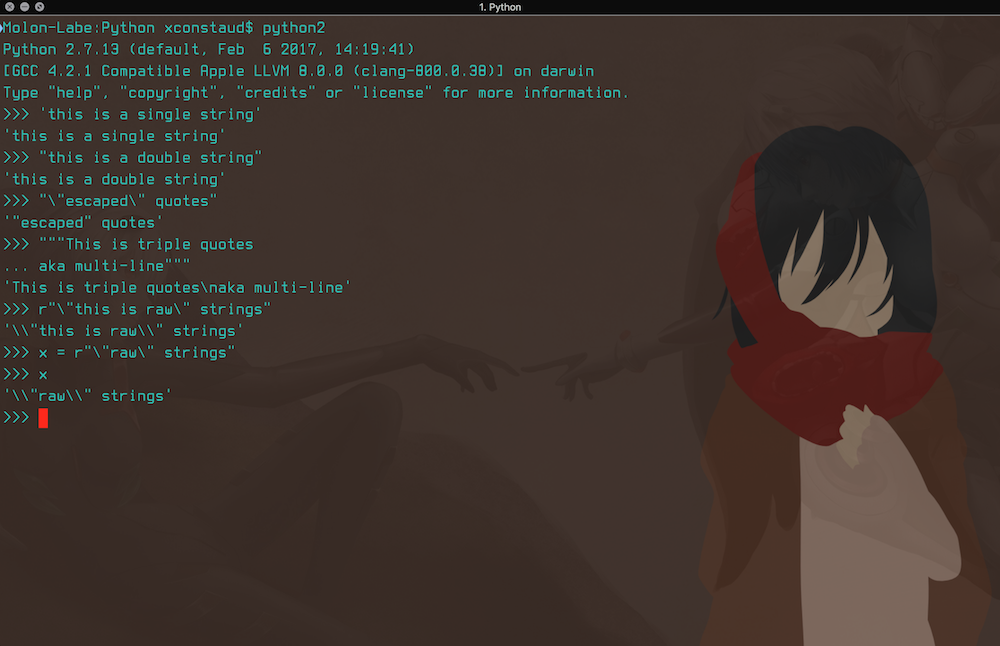
To declare a string, use one of the following. There is no Pythonic way aside from keeping it as simple and clean as possible.
- 'single quotes'
- "double quotes"
- ""escaped" quotes"
- """triple quoted-multiline"""
- r""raw" strings"
String Prefixes
- u or U for Unicode
- r or R for raw string literal (ignores escape characters)
- b or B for byte… is ignored in Python 2 since str is bytes.
- A ‘u’ or ‘b’ prefix may be followed by a ‘r’ prefix.
Yes, this stuff is old school and not very Pythonic... but it can't be helped.
Difference between ASCII and Unicode (utf-8)
ASCII defines 128 characters, mapped 0-127. Unicode on the other hand defines less than 2^21 characters, mapped 0-2^21. It is worth noting that not all Unicode numbers are assigned yet. Unicode numbers 0-128 have the same meaning as ASCII values; but do not fit into one 8-bit block of memory like ASCII values do. Thus Unicode in Python 3 utilizes utf-8 which allows for the use of multiple 8-bit blocks of memory.
Byte String vs Data String
Byte Strings are simply just a sequence of bytes. In Python 2, bytes is an alias of str. In other words, they are used interchangeably. In Python 3 on the other hand, str is it's own type... utilizing Unicode (utf-8). Whereas the bytes type in Python 3 is still a bytes object in ASCII; an array of integers.
Python 2
>>> x = "I am a string"
>>> type(x)
<type 'str'>
>>> x
'I am a string'
>>> hex(ord(x[0]))
0x49
Python 3
>>> x = 'I am a string'.encode('ASCII')
>>> type(x)
<class 'bytes'>
>>> print(hex(x[0]))
0x49 # ASCII code for capital I
>>> x = b'I am a string' # Doing this in Python 2 makes no difference
>>> type(x)
<class 'bytes'>
Unicode Strings
Python 2
>>> x = u"I am a unicode string"
>>> type(x)
<type 'unicode'>
>>> y = unicode("Look at me! I’m a unicode string.")
>>> type(y)
<type 'unicode'>
# You can use ‘…’ quotes “…” quotes or “””…””” quotes
Python 3
>>> x = 'I am a unicode string'
>>> type(x)
<class 'str'>
# class str is unicode in Python 3 natively
# You can use ‘…’ quotes “…” quotes or “””…””” quotes
Slicing
Slicing allows you to grab a substring of a string. Python's indexing structure starts at 0. The only exception is when grabbing an element using a negative index. There is an example further below.
Grabbing a specific element
>>> x = "hello world"
>>> print(x[4]) # grabs 4th index
o
Grab a range of elements
>>> x = "hello world"
>>> print(x[4:9]) # grabs 4th index up until, but not including the 9th index.
o wor
Grabbing backwards from the last element
>>> x = "hello world"
>>> print(x[-3]) # grabs the 3rd to the last ELEMENT
r
- Slicing with negative values start at -1, not 0. So if we have a string (x = "test"... t= -4, e = -3 s = -2 t = -1)... Thus a -2 slice will grab the 's'.
- When slicing a range, you grab everything UPTO (not including) the second defined index number.
More String Manipulation
- Try the following
>>> my_string = "Hello World!"
>>> print(my_string[0])
H
>>> print(my_string[0:5])
Hello
>>> print(my_string[6:])
World!
>>> print(my_string[-6:]) # ???
>>> print(my_string[::2]) # ???
>>> print(my_string * 2) # ???
>>> print(my_string + my_string) # ???
What did you get? Try different operations to manipulate strings!
String Special Operators
| Operator | Description |
|---|---|
| + | Concatenation |
| * | Repetition |
| [] | Slice |
| [:] | Range Slice |
| in | Membership - returns true if a character exists |
| not in | Membership - returns true if a character does not exist |
| % | Format |
User Input
There are a few ways to capture user input in Python. The most common are raw_input() in Python 2 and input() in Python 3. It is important that you use raw_input() in Python 2... as input() has security vulnerabilities. In Python 3, input() takes user input as a string, no matter the input. On the other hand, input() in Python 2 will take user input as the type presented. This can lead to users implementing false bools and such.
Python 2
>>> name = raw_input("What is your name? ")
What is your name? <user input>
>>> name
<user input>
Python 3
>>> name = input("What is your name? ")
What is your name? <user input>
>>> name
<user input>
As you more than likely guessed, the user input is assigned to the variable name and stored as a string. From here, you can treat var name as any other regular string.
Useful String Methods
- string.upper() # Outputs string as uppercase
- string.lower() # Outputs string as lowercase
- len(string) # Outputs string length
- symbol.join(string/list) # Most commonly used to join list items, outputs string.
- string.split(symbol )# Most commonly used to split a string up into a list of items, outputs list.
>>> my_string = "Hello World!”"
>>> a = my_string.upper()
>>> print(a)
'HELLO WORLD!'
>>> a = my_string.lower()
>>> print(a)
'hello world!'
>>> a = len(my_string)
>>> print(a)
12
>>> a = my_string.split(" ")
['Hello', 'World!']
>>> print(my_string)
'Hello World!'
>>> my_string = "+".join(a)
>>> print(my_string)
'Hello+World!'
Changing a Character
>>> my_string = "Hello World!"
>>> my_string[1]
'e'
>>> my_string[1] = 'E'
What's the outcome? How does replace() work?
Join
join() combines sequential string elements by a specified _str _separator. If no separator is specified join will insert white space by default.
Syntax:
str.join(sequence)
Example:
s = "-";
seq = ("a", "b", "c"); # This is sequence of strings.
print(s.join( seq ))
#Output: a-b-c
Split
split() will breakup a string and add the data to a string array using a defined separator.
Syntax:
str.split(str="", num=string.count(str))
#str - any delimeter, by default it is space.
#num - number of lines minus one.
Example:
x = 'blue,red,green'
x.split(",")
['blue', 'red', 'green']
>>>
>>> a,b,c = x.split(",")
>>> a
'blue'
>>> b
'red'
>>> c
'green'
Additional Standard Library Functionality
- startswith, endswith
- find, rfind
- count
- isalnum
- strip
- capitalize
- title
- upper, lower
- swapcase
- center
- ljust, rjust
Continue to Performance Labs: 2D and 2E